论文: Visualizing and Understanding Recurrent Networks
实验设定
字母级的循环神经网络,用Torch实现,代码见GitHub。字母嵌入成One-hot向量。优化方面,采用了RMSProp算法,加入了学习速率的decay和early stopping。
数据集采用了托尔斯泰的《战争与和平》和Linux核心的代码。
可解释性激活的例子
$tanh$函数激活的例子,$-1$为红色,$+1$为蓝色。
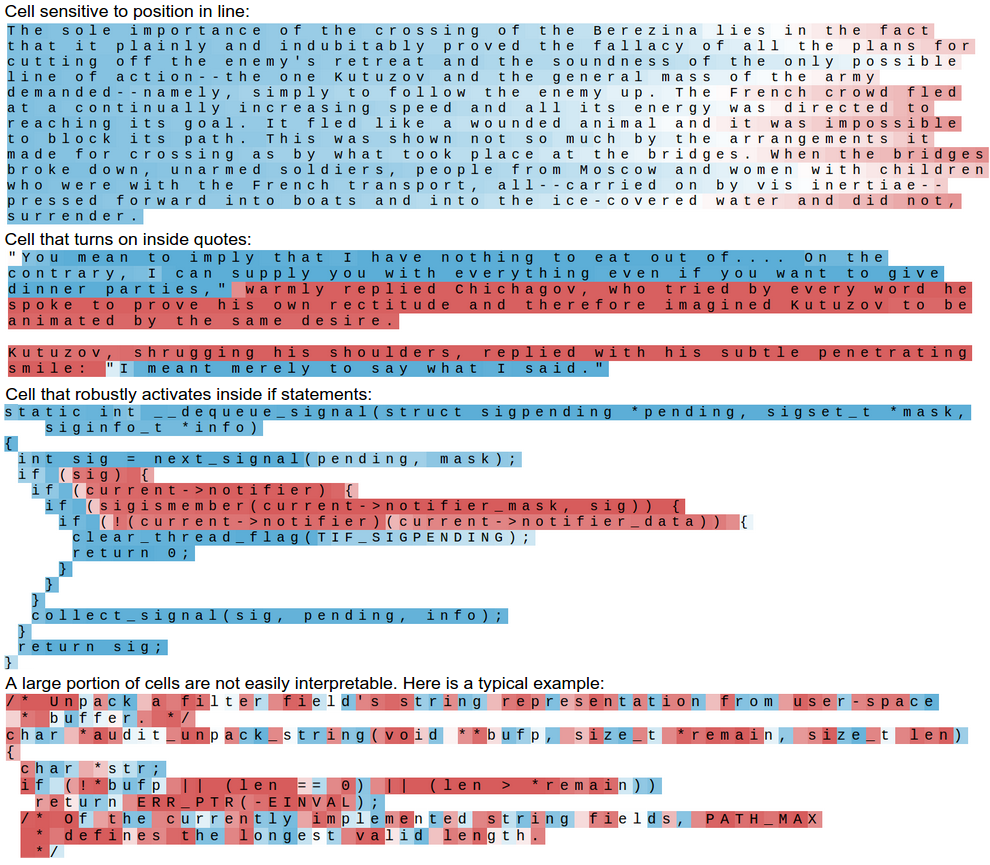
上图分别是记录了行位置、引文和if语句特征的例子和失败的例子。

上图分别是记录代码中注释、代码嵌套深度和行末标记特征的例子。
Gates数值的统计
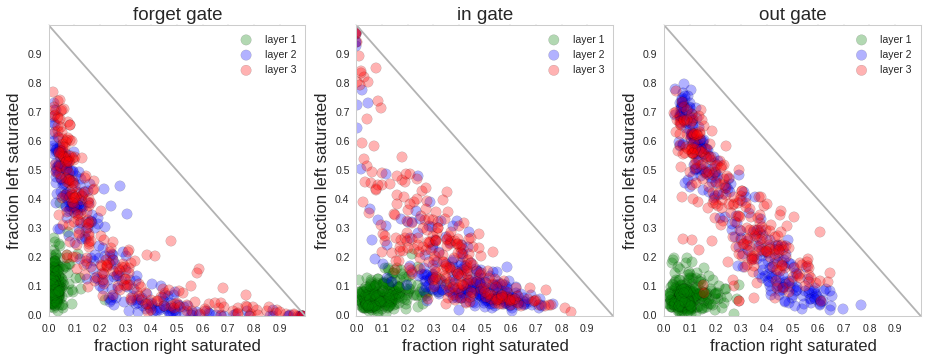
此图信息量很大。
- left-saturated和right-saturated表示各个Gates激活函数($sigmoid$)小于0.1和大于0.9,即总是阻止信息流过和总是允许信息流过。
- 横轴和纵轴表示该Gate处于这两种状态的时间比例,即有多少时间是阻塞状态,有多少时间是畅通状态。
- 三种颜色表示不同的层。
有以下几个观察:
- 第一层的门总是比较中庸,既不阻塞,也不畅通
- 第二三层的门在这两种状态间比较分散,经常处于畅通状态的门可能记录了长期的依赖信息,而经常处于阻塞状态的门则负责了短期信息的控制。
错误来源分析
在这一节,作者用了“剥洋葱”的方法,建立了不同的模型将错误进行分解。此处错误指LSTM预测下一个字母产生的错误,数据集为托尔斯泰的《战争与和平》。
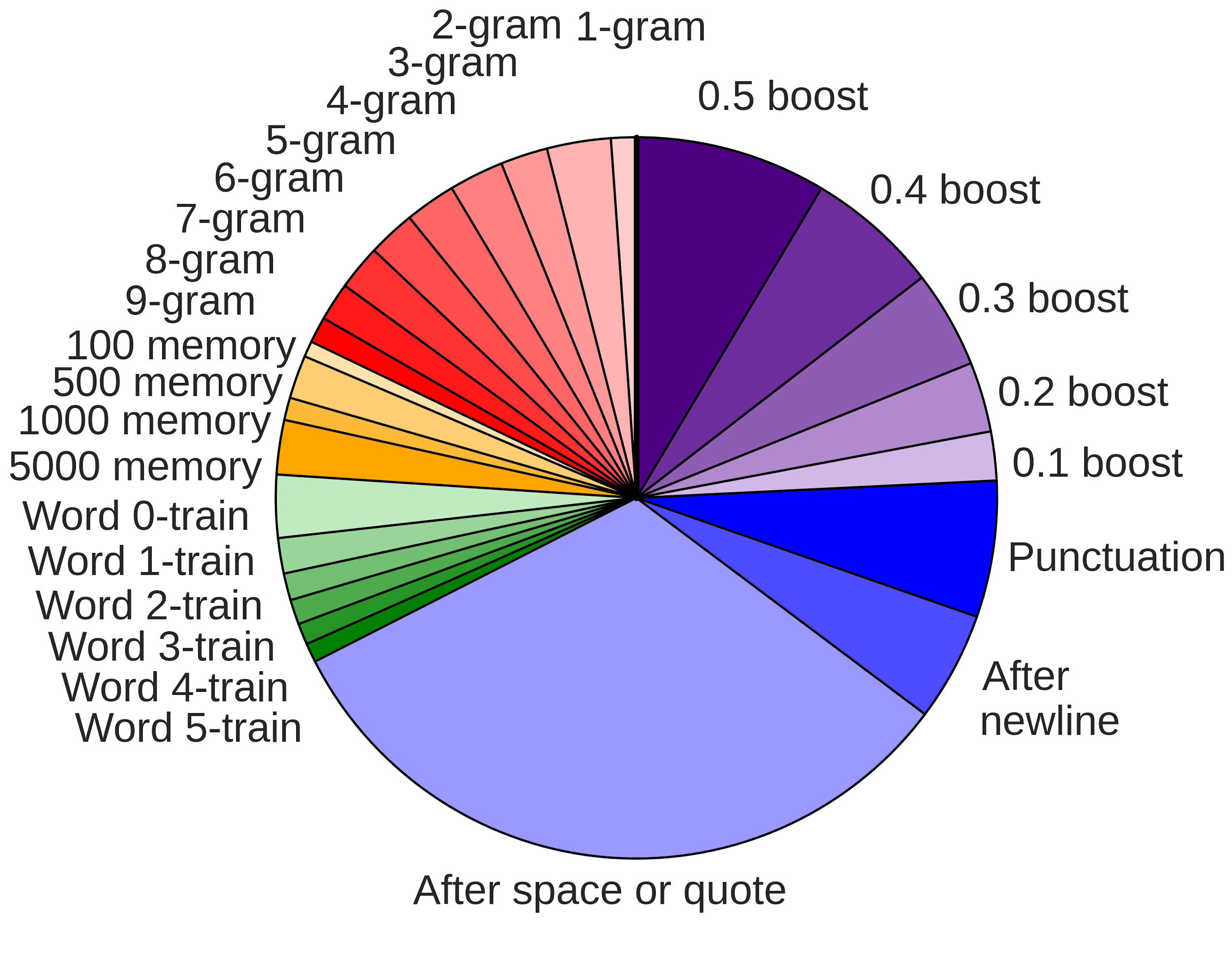
- n-gram
- Dynamic n-long memory,即对已经出现过得单词的复现。如句子”Jon yelled at
Mary but Mary couldn’t hear him.”中的Mary。 - Rare words,不常见单词
- Word model,单词首字母、新行、空格之后出现的错误
- Punctuation,标点之后
- Boost,其他错误
根据作者的实验,错误的来源有如下分解:
小结
这篇文章是打开LSTM黑箱的尝试,提供了序列维度上共享权值的合理性证据,对Gates状态的可视化也非常值得关注,最后对误差的分解可能对新的网络结构有所启发(比如,如何将单词级别和字母级别的LSTM嵌套起来,解决首字母预测的问题?)。