Dropout技术是Srivastava等人在2012年提出的技术,现在已然成为各种深度模型的标配。其中心思想是随机地冻结一部分模型参数,用于提高模型的泛化性能。
Dropout的洞察
关于Dropout,一个流行的解释是,通过随机行为训练网络,并平均多个随机决定的结果,实现了参数共享的Bagging。如下图,通过随机地冻结/抛弃某些隐藏单元,我们得到了新的子网络,而参数共享是说,与Bagging中子模型相互独立的参数不同,深度网络中Dropout生成的子网络是串行的,后一个子模型继承了前一个子模型的某些参数。
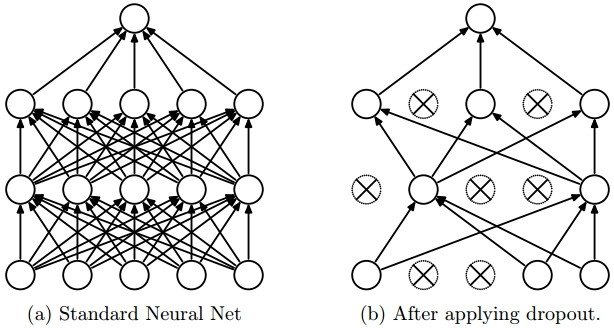
Dropout是模型自我破坏的一种形式,这种破坏使得存活下来的部分更加鲁棒。例如,某一隐藏单元学得了脸部鼻子的特征,而在Dropout中遭到破坏,则在之后的迭代中,要么该隐藏单元重新学习到鼻子的特征,要么学到别的特征,后者则说明,鼻子特征对该任务来说是冗余的,因而,通过Dropout,保留下来的特征更加稳定和富有信息。
Hinton曾用生物学的观点解释这一点。神经网络的训练过程可以看做是生物种群逐渐适应环境的过程,在迭代中传递的模型参数可以看做种群的基因,Dropout以随机信号的方式给环境随机的干扰,使得传递的基因不得不适应更多的情况才能存活。
另一个需要指出的地方是,Dropout给隐藏单元加入的噪声是乘性的,不像Bias那样加在隐藏单元上,这样在进行反向传播时,Dropout引入的噪声仍能够起作用。
代码实现
下面看在实践中,Dropout层是如何实现的。简单来说,就是生成一系列随机数作为mask,然后再用mask点乘原有的输入,达到引入噪声的效果。
From Scratch
# forward pass
def dropout_forward(x, dropout_param):
p, mode = dropout_param['p'], dropout_param['mode']
# p: dropout rate; mode: train or test
if 'seed' in dropout_param:
np.random_seed(dropout_param['seed'])
# seed: random seed
mask = None
out = None
if mode == 'train':
mask = (np.random.rand(*x.shape) >= p)/(1-p)
# 1-p as normalization multiplier: to keep the size of input
out = x * mask
elif mode == 'test':
# do nothing when perform inference
out = x
cache = (dropout_param, mask)
out = out.astype(x.dtype, copy=False)
return out, cache
# backward pass
def dropout_backward(dout, cache):
dropout_param, mask = cache
mode = dropout_param['mode']
dx = None
if mode == 'train':
dx = dout * mask
elif mode == 'test':
dx = dout
return dx
Pytorch实现
file: /torch/nn/_functions/dropout.py
class Dropout(InplaceFunction):
def __init__(self, p=0.5, train=False, inplace=False):
super(Dropout, self).__init__()
if p < 0 or p > 1:
raise ValueError("dropout probability has to be between 0 and 1, "
"but got {}".format(p))
self.p = p
self.train = train
self.inplace = inplace
def _make_noise(self, input):
# generate random signal
return input.new().resize_as_(input)
def forward(self, input):
if self.inplace:
self.mark_dirty(input)
output = input
else:
output = input.clone()
if self.p > 0 and self.train:
self.noise = self._make_noise(input)
# multiply mask to input
self.noise.bernoulli_(1 - self.p).div_(1 - self.p)
if self.p == 1:
self.noise.fill_(0)
self.noise = self.noise.expand_as(input)
output.mul_(self.noise)
return output
def backward(self, grad_output):
if self.p > 0 and self.train:
return grad_output.mul(self.noise)
else:
return grad_output