本作是Inception系列网络的第一篇,提出了Inception单元结构,基于这一结构的GoogLeNet拿下了ILSVRC14分类任务的头名。文章也探讨了网络在不断加深的情况下如何更好地利用计算资源,这一理念也是Inception系列网络的核心。
Motivation
Inception单元的启发主要来自Network in Network结构和Arora等人在神经科学方面的工作。
提高深度模型的一个简单想法是增加深度,但这样带来过拟合的风险和巨大的计算资源消耗,对数据量和计算力的要求可能会超过网络加深带来的收益。
解决这些问题的基本思路是使用稀疏连接的网络,而这也跟Arora等人工作中的Hebbian principle吻合:共同激活的神经元常常集聚在一起。换句话说,某一层激活的神经元只向下一层中特定的几个神经元传递激活信号,而向其他神经元几乎不传递信息,即仅有少部分连接是真正有效的,这也是稀疏的含义。
然而另一方面,现代计算架构对稀疏的计算非常低效,更适合的是密集的计算,这样便产生了矛盾。而Inception单元的提出就是为了用密集的结构来近似稀疏结构,在建模稀疏连接的同时又能利用密集计算的优势。
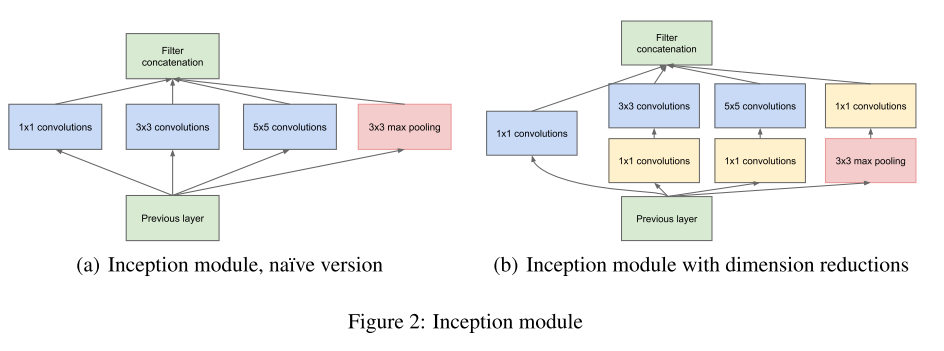
很多文章认为inception结构的意义在于将不同大小核的卷积并行连接,然后让网络自行决定采用哪种卷积来提取特征,有些无监督的意味,然后将1×1的卷积解释为降维操作。这种想法有待验证,是否在5×5卷积有较强激活的时候,3×3卷积大部分没有激活,还是两者能够同时有较强的激活?不同的处理阶段这两种卷积核的选择有没有规律?
在此提出一个个人的理解,欢迎讨论。
首先是channel的意义。我们知道,卷积之所以有效,是因为它建模了张量数据在空间上的局部相关性,加之Pooling操作,将这些相关性赋予平移不变性(即泛化能力)。而channel则是第三维,它实际上是卷积结构中的隐藏单元,是中间神经元的个数。卷积层在事实上是全连接的:每个Input channel都会和output channel互动,互动的信息只不过从全连接层的weight和bias变成了卷积核的weight。
这种全连接是冗余的,本质上应是一个稀疏的结构。Inception单元便在channel这个维度上做文章,采用的是类似矩阵分块的思想。
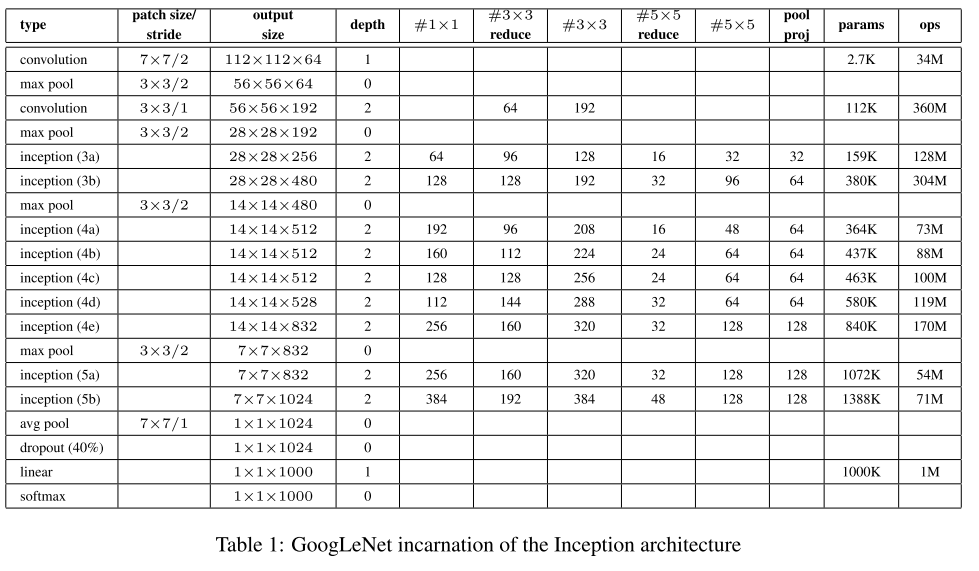
根据Hebbian principle,跨channel的这些神经元,应是高度相关的,于是有信息压缩的空间,因而使用跨channel的1×1的卷积将它们嵌入到低维的空间里(比如,Inception4a单元的输入channel是512,不同分支的1×1卷积输出channel则是192,96,16和64,见下面GoogLeNet结构表),在这个低维空间里,用密集的全连接建模(即3×5和5×5卷积),它们的输出channel相加也再恢复到原来的输入channel维度(Inception4a分别是192+208+48+64),最后的连接由Concat操作完成(分块矩阵的合并),这样就完成了分块密集矩阵对稀疏矩阵的近似。
这样来看,3×3和5×5大小的选择并不是本质的,本质的是分块低维嵌入和concat的分治思路。而在ResNeXt的工作中,这里的分块被认为是新的维度(称为cardinality),采用相同的拓扑结构。
Stacked Inception Module
在GoogLeNet中,借鉴了AlexNet和VGG的stack(repeat)策略,将Inception单元重复串联起来,构成基本的特征提取结构。
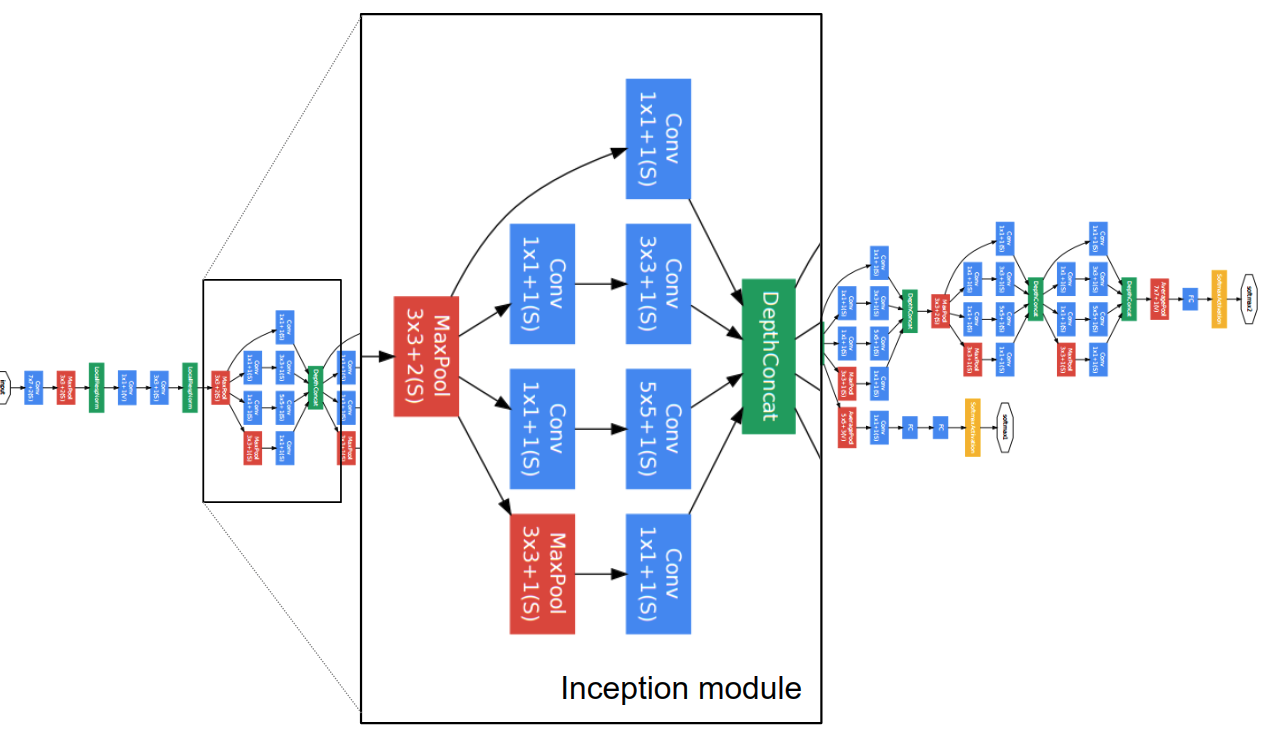
Dimension Reduction
朴素版本的Inception单元会带来Channel维数的不断增长,加入的1×1卷积则起到低维嵌入的作用,使Inception单元前后channel数保持稳定。
Auxililary Classifier
这里是本文的另一个贡献,将监督信息传入中间的feature map,构成一个整合loss,作者认为这样有助于浅层特征的学习。
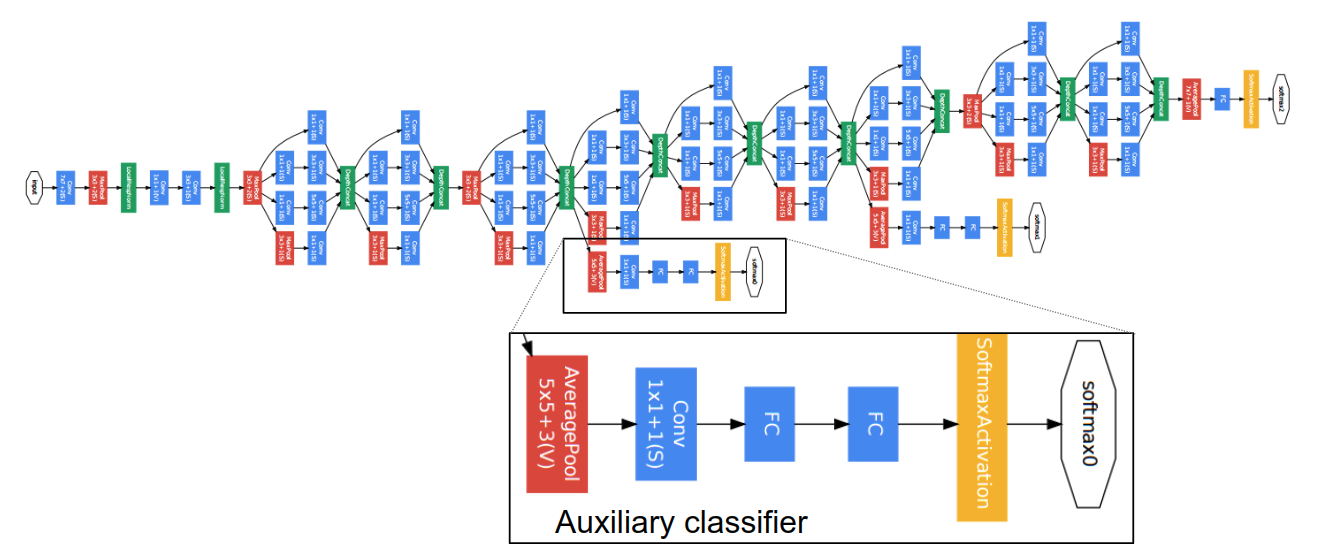
Architecture of GoogLeNet
下面的表显示了GoogLeNet的整体架构,可以留意到Inception单元的堆叠和Channel数在子路径中的变化。NetScope可视化可参见GoogLeNet Vis。源文件位于awesome_cnn。
Conclusion
文章是对NiN思想的继承和推进,不同于AlexNet和VGG,网络的模块化更加凸显,多路径的结构也成为新的网络设计范本,启发了众多后续网络结构的设计。