本篇论文介绍了旷视取得2017 MS COCO Detection chanllenge第一名的模型。提出大批量训练检测网络,并用多卡BN保证网络的收敛性。
Object Detection Progress Summay
检测方法回顾:R-CNN, Fast/Faster R-CNN, Mask RCNN, RetinaNet(Focal Loss), ResNet(backbone network),
文章先指出前述方法大多是框架、loss等的更新,而均采用非常小的batch(2张图片)训练,有如下不足:
- training slow
- fails to provide accurate statistics for BN
这里涉及一个问题,检测任务的源数据,到底应该是图片还是标注框。在Fast R-CNN中,RBG提到SPPNet等每个batch采样的标注框来自不同的图片,之间不能共享卷积运算(卷积运算是以图片为单位的)。为了共享这部分计算,Fast R-CNN采用了“先选图片,再选标注框”的策略来确定每个batch,文章提到这种操作会引入相关性,但在实际中却影响不大。之后的Faster R-CNN,每张图片经过RPN产生约300个Proposal,传入RCNN做法也成了通用做法。
个人认为检测任务的数据,应该是以图片为单位的。物体在图片的背景中才会产生语义,而尽管每张图片有多个Proposal(近似分类任务中的batch大小),但它们共享的是同一个语义(场景),而单一的语义难以在同一个batch中提供多样性来供网络学习。
困境
Increasing mini-batch size requires large learning rate, which may cause discovergence.
解决方案
- new explanation of linear scaling rule, introduce “warmup” trick to learning rate schedule
- Cross GPU Batch Normalization(CGBN)
Approach
Variance Equivalence explanation for Linear Scaling Rule
linear scaling rule 来自更改batch size 时,同时放缩learning rate,使得更改后的weight update相比之前小batch size, 多步的weight update类似。而本文用保持loss gradient的方差不变重新解释了linear scaling rule,并指出这一假定仅要求loss gradient是i.i.d,相比保持weight update所假设的不同batch size间loss gradient相似更弱。
参见Accurate Large Minibatch SGD: Training ImageNet in One Hour,近似时假设了求和项变化不大,这一条件在Object Detection中可能不成立,不同图片的标注框(大小、个数)差别很大。
WarmUp Strategy
在训练初期,weight抖动明显,引入warmup机制来使用较小的学习率,再逐渐增大到Linear scaling rule要求的学习率。
Cross-GPU Batch Normalization
BN是使深度网络得以训练和收敛的关键技术之一,但在检测任务中,fine-tuning阶段常常固定了SOTA分类网络的BN部分参数,不进行更新。
检测中常常需要较大分辨率的图片,而GPU内存限制了单卡上的图片个数,提高batch size意味着BN要在多卡(Cross-GPU)上进行。
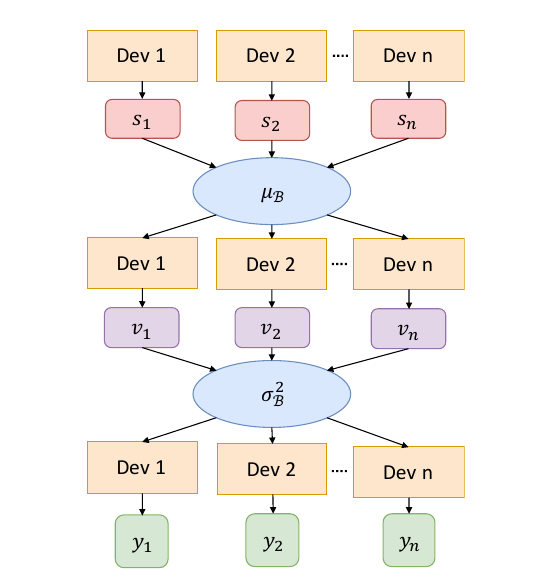
BN操作需要对每个batch计算均值和方差来进行标准化,对于多卡,具体做法是,单卡独立计算均值,聚合(类似Map-Reduce中的Reduce)算均值,再将均值下发到每个卡,算差,再聚合起来,计算batch的方差,最后将方差下发到每个卡,结合之前下发的均值进行标准化。
流程如图:
Experiments
在COCO数据集上的架构用预训练ResNet-50作为基础网络,FPN用于提供feature map。
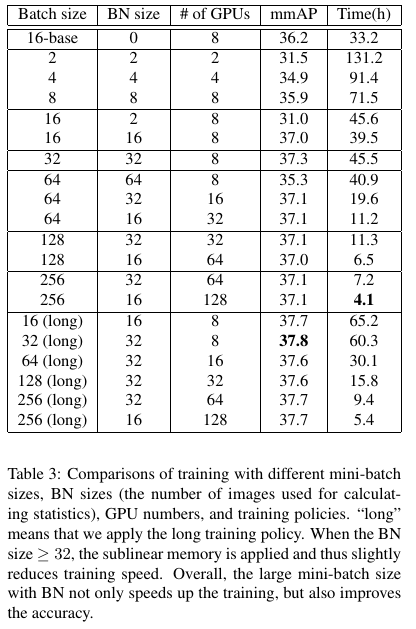
结果显示,不使用BN时,较大的batch size(64,128)不能收敛。使用BN后,增大Batch size能够收敛但仅带来较小的精度提升,而BN的大小也不是越大越好,实验中,32是最好的选择。主要结果如下表:
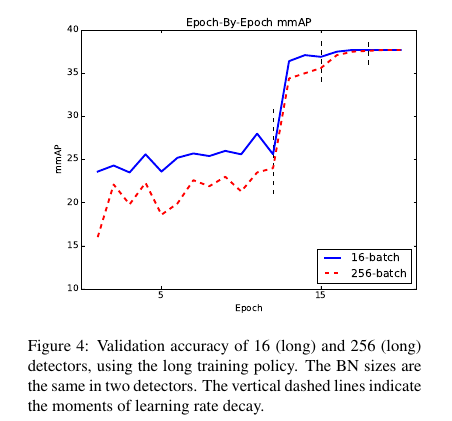
按epoch,精度的变化如下图,小batch(16)在最初的几个epoch表现比大batch(32)要好。
小结
这篇论文读起来总感觉少了些东西。对Linear scale rule的解释固然新颖,但没有引入新的trick(只是确认了检测仍是需要Linear scale rule的)。多卡的BN确实是非常厉害的工程实现(高效性),但实验的结果并没有支持到较大的batch size(128,256)比小batch精度更好的期望,而最后的COCO夺冠模型整合了多种trick,没有更进一步的错误分析,很难支撑说明CGBN带来的关键作用。