文章指出两阶段检测器通常在生成Proposal后进行分类的“头”(head)部分进行密集的计算,如ResNet为基础网络的Faster-RCNN将整个stage5(或两个FC)放在RCNN部分, RFCN要生成一个具有随类别数线性增长的channel数的Score map,这些密集计算正是两阶段方法在精度上领先而在推断速度上难以满足实时要求的原因。
针对这两种元结构(Faster-RCNN和RFCN),文章提出了“头”轻量化方法,试图在保持精度的同时又能减少冗余的计算量,从而实现精度和速度的Trade-off。
Light-Head R-CNN
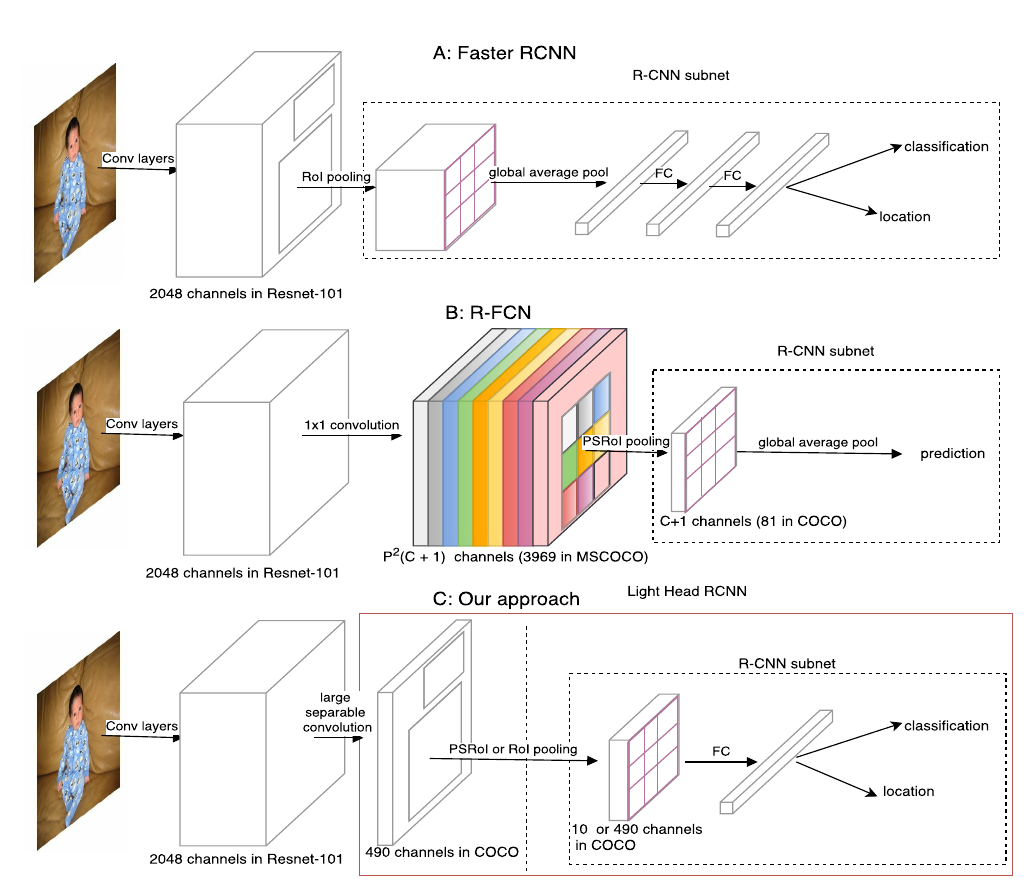
如上图,虚线框出的部分是三种结构的RCNN子网络(在每个RoI上进行的计算),light-head R-CNN中,在生成Score map前,ResNet的stage5中卷积被替换为sperable convolution,产生的Score map也减少至10×p×p(相比原先的#class×p×p)。
一个可能的解释是,“瘦”(channel数较少)的score map使用于分类的特征信息更加紧凑,原先较“厚”的score map在经过PSROIPooling的操作时,大部分信息并没有提取(只提取了特定类和特定位置的信息,与这一信息处在同一score map上的其他数据都被忽略了)。
进一步地,位置敏感的思路将位置性在channel上表达出来,同时隐含地使用了更类别数相同长度的向量表达了分类性(这一长度相同带来的好处即是RCNN子网络可以免去参数)。
light-head在这里的改进则是把这一个隐藏的嵌入空间压缩到较小的值,而在RCNN子网络中加入FC层再使这个空间扩展到类别数的规模,相当于是把计算量分担到了RCNN子网络中。
粗看来,light-head将原来RFCN的score map的职责两步化了:thin score map主攻位置信息,RCNN子网络中的FC主攻分类信息。另外,global average pool的操作被去掉,用于保持精度。
Experiments
实验部分,文章验证了较“瘦”的Score map不会对精度产生太大损害,也展现了ROI Align, Multiscale train等技巧对基线的提升过程。
文章的主要结果如下面两图(第一个为高精度,第二个为高速度):
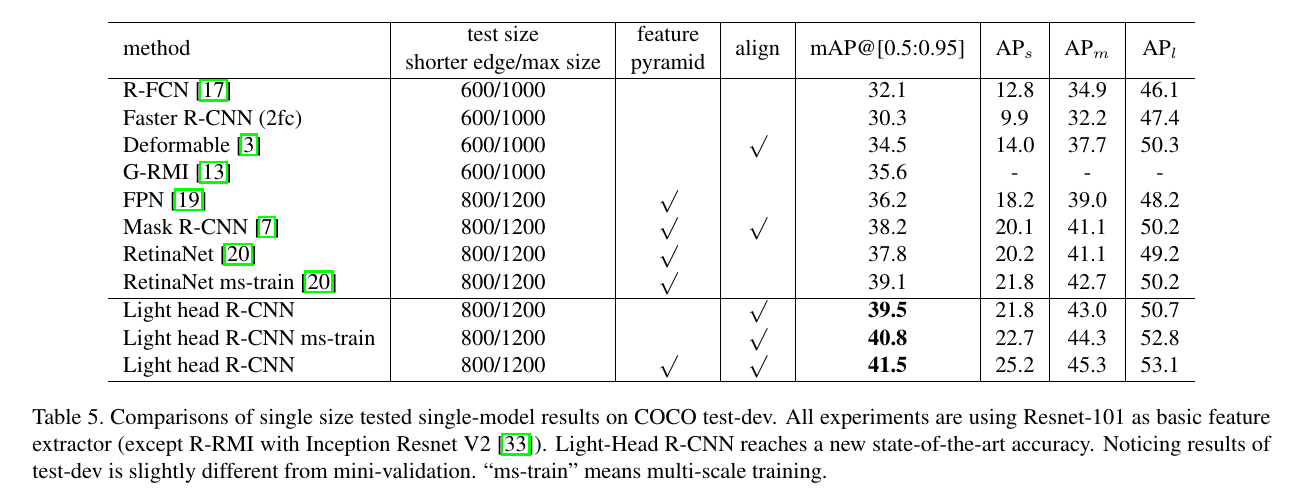
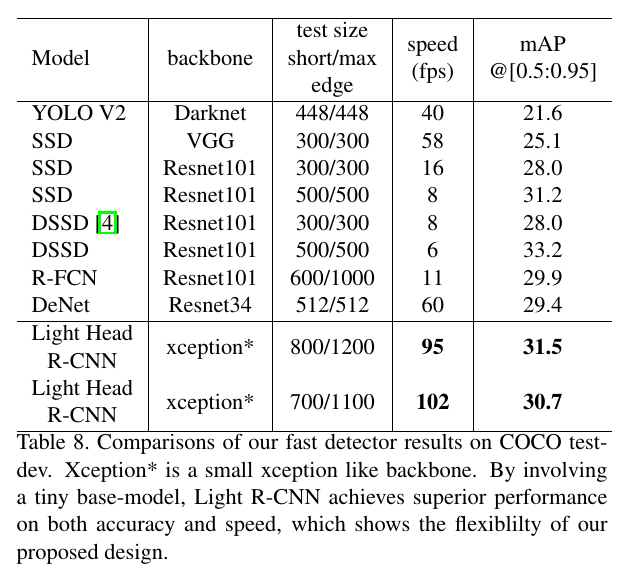
只能说这样的对比比较诡异。
第一张图中三个light-head结果并不能跟上面的其他结构构成多少有效的对照组,要么scale不同,要么FPN, multi-scale, ROI Align不同。唯一的有效对照是跟Mask-RCNN。
在高精度方面,基础网络不同,采用的scale也不同,没有有效的对照组。
Conclusion
我并不觉得这是对两阶段方法的Defense。文章对两阶段方法在精度和速度方面的分析比较有见地,但实验的结果并不能可靠地支撑light-head的有效性。相比之下Google的那篇trade-off可能更有参考价值。