YOLO是单阶段方法的开山之作。它将检测任务表述成一个统一的、端到端的回归问题,并且以只处理一次图片同时得到位置和分类而得名。
YOLO的主要优点:
- 快。
- 全局处理使得背景错误相对少,相比基于局部(区域)的方法, 如Fast RCNN。
- 泛化性能好,在艺术作品上做检测时,YOLO表现好。
Design
YOLO的大致工作流程如下:
1.准备数据:将图片缩放,划分为等分的网格,每个网格按跟ground truth的IOU分配到所要预测的样本。
2.卷积网络:由GoogLeNet更改而来,每个网格对每个类别预测一个条件概率值,并在网格基础上生成B个box,每个box预测五个回归值,四个表征位置,第五个表征这个box含有物体(注意不是某一类物体)的概率和位置的准确程度(由IOU表示)。测试时,分数如下计算:
等式左边第一项由网格预测,后两项由每个box预测,综合起来变得到每个box含有不同类别物体的分数。
因而,卷积网络共输出的预测值个数为S×S×(B×5+C),S为网格数,B为每个网格生成box个数,C为类别数。
3.后处理:使用NMS过滤得到的box
Loss
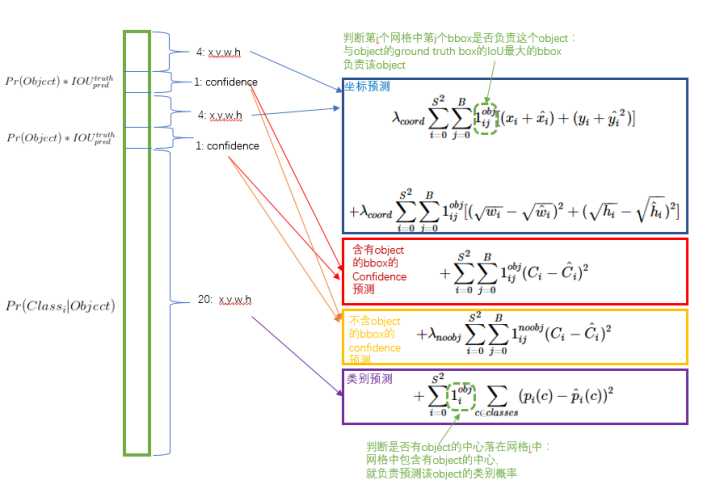
图片来自https://zhuanlan.zhihu.com/p/24916786
损失函数被分为三部分:坐标误差、物体误差、类别误差。为了平衡类别不均衡和大小物体等带来的影响,loss中添加了权重并将长宽取根号。
Error Analysis
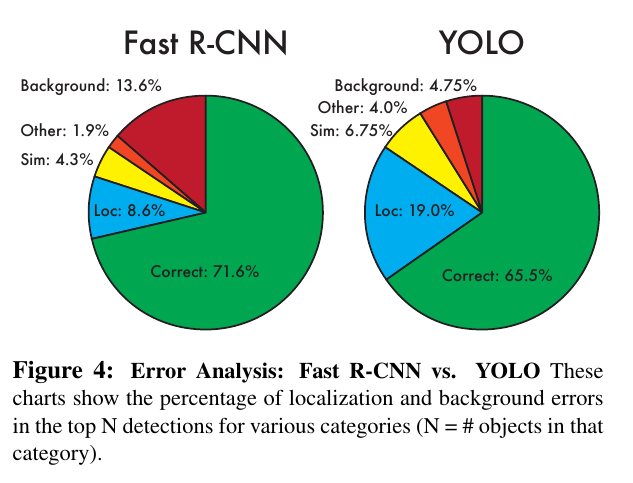
相比Fast-RCNN,YOLO的背景误检在错误中占比重小,而位置错误占比大(未采用log编码)。
Limitations
YOLO划分网格的思路还是比较粗糙的,每个网格生成的box个数也限制了其对小物体和相近物体的检测。
Conclusion
YOLO提出了单阶段的新思路,相比两阶段方法,其速度优势明显,实时的特性令人印象深刻。