基于动态图的深度学习框架如Pytorch,DyNet提供了更为灵活的结构和数据维度的选择,但要求开发者自行将数据批量化,才能最大限度地发挥框架的并行计算优势。
当前的状况:灵活的结构与高效计算
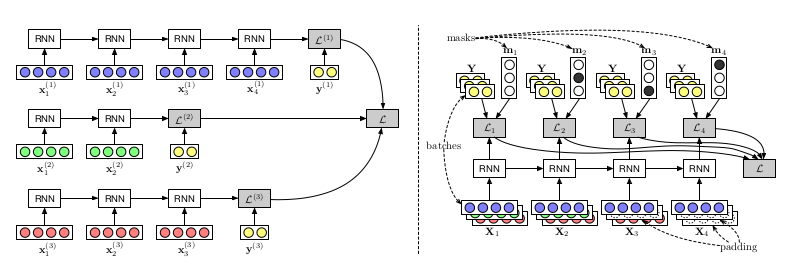
左图为循环结构,右图将序列补齐,批量化
- 灵活的结构和数据输入维度,采用朴素的循环结构实现,但不高效,因为尽管维度不同,在循环内数据接受的是同样的操作。

- 对数据做“Padding”,即用傀儡数据将输入维度对齐,进而实现向量化,但这种操作对开发者并不友好,会使开发者浪费掉很多本该投入到结构设计等方面的精力。

本文提出的方法
三个部分
- Graph Definition
- Operation Batching
- Computation
第一步和第三步在当前已被大部分深度学习框架较好地实现。主要特点是,构建计算图与计算的分离,即”Lazy Evaluation”。比如在Tensorflow中,一个抽象层负责解析计算图各节点之间的依赖,决定执行计算的顺序,而另一个抽象层则负责分配计算资源。
Operation Batching
Computing compatibility groups
这一步是建立可以批量化计算的节点组。具体做法是,给每一个计算节点建立 signature,用于描述节点计算的特性,文中举出了如下几个例子:
- Component-wise operations: 直接施加在每个张量元素上的计算,跟张量的维度无关,如$tanh$,$log$
- Dimension-sensitive operations: 基于维度的计算,如线性传递$Wh+b$,要求$W$和$h$维度相符,signature 中要包含维度信息
- Operations with shared elements: 包含共享元素的计算,如共享的权值$W$
- Unbatchable operations: 其他
Determining execution order
执行顺序要满足两个目标:
- 每一节点的计算要在其依赖之后
- 带有同样 signature 且没有依赖关系的节点放在同一批量执行
但在一般情况下找到最大化批量规模的执行顺序是个NP问题。有如下两种策略:
- Depth-based Batching: 库
Tensorflow Fold中使用的方法。某一节点的深度定义为其子节点到其本身的最大长度,同一深度的节点进行批量计算。但由于输入序列长度不一,可能会错失一些批量化的机会。 - Agenda-based Batching: 本文的方法,核心的想法是维护一个 agenda 序列,所有依赖已经被解析的节点入列,每次迭代时从 agenda 序列中按 signature 相同的原则取出节点进行批量计算。
实验
文章选取了四个模型:BiLSTM, BiLSTM w/char, Tree-structured LSTMs, Transition-based Dependency Parsing。
实验结果:(单位为Sentences/second)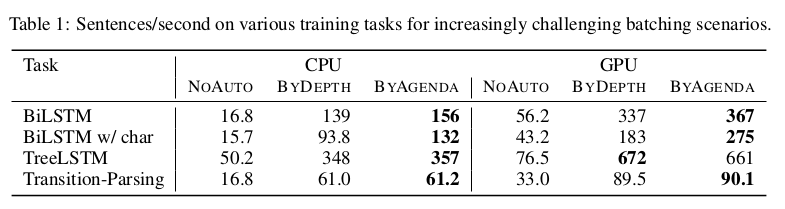
小结
本来读到题目还是蛮惊喜的,期待的是从模型构建的角度解决序列长度不一带来的计算上的不便。但通读下来发现是在计算图的计算这一层面进行的优化,有些失望但也感激,作者使用DyNet框架实现了他们的方法,希望自己也可以为Pytorch等框架该算法的实现出一份力。
感谢这些开源的框架,正一步步拉近人类构建模型和机器高效计算之间的距离。
论文链接:On-the-fly Operation Batching in Dynamic Computaion Graphs