对图片信息的理解常常关系到对位置和规模上不变性的建模。在较为成功的图片分类模型中,Max-Pooling这一操作建模了位置上的不变性:从局部中挑选最大的响应,这一响应在局部的位置信息就被忽略掉了。而在规模不变性的方向上,添加不同大小感受野的卷积核(VGG),用小卷积核堆叠感受较大的范围(GoogLeNet),自动选择感受野的大小(Inception)等结构也展现了其合理的一面。
回到检测任务,与分类任务不同的是,检测所面临的物体规模问题是跨类别的、处于同一语义场景中的。
一个直观的思路是用不同大小的图片去生成相应大小的feature map,但这样带来巨大的参数,使本来就只能跑个位数图片的内存更加不够用。另一个思路是直接使用不同深度的卷积层生成的feature map,但较浅层的feature map上包含的低等级特征又会干扰分类的精度。
本文提出的方法是在高等级feature map上将特征向下回传,反向构建特征金字塔。
Feature Pyramid Networks
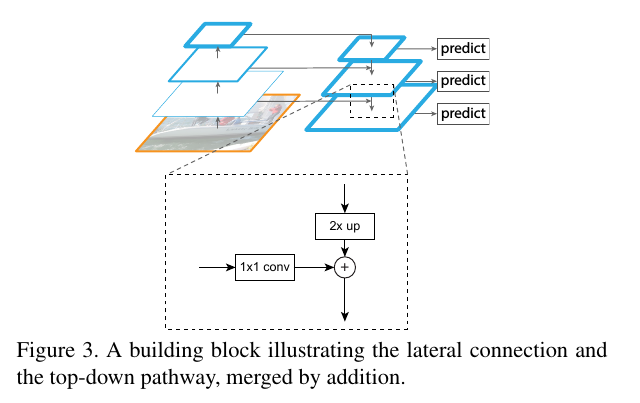
从图片开始,照常进行级联式的特征提取,再添加一条回传路径:从最高级的feature map开始,向下进行最近邻上采样得到与低等级的feature map相同大小的回传feature map,再进行元素位置上的叠加(lateral connection),构成这一深度上的特征。
这种操作的信念是,低等级的feature map包含更多的位置信息,高等级的feature map则包含更好的分类信息,将这两者结合,力图达到检测任务的位置分类双要求。
Experiments
文章的主要实验结果如下:
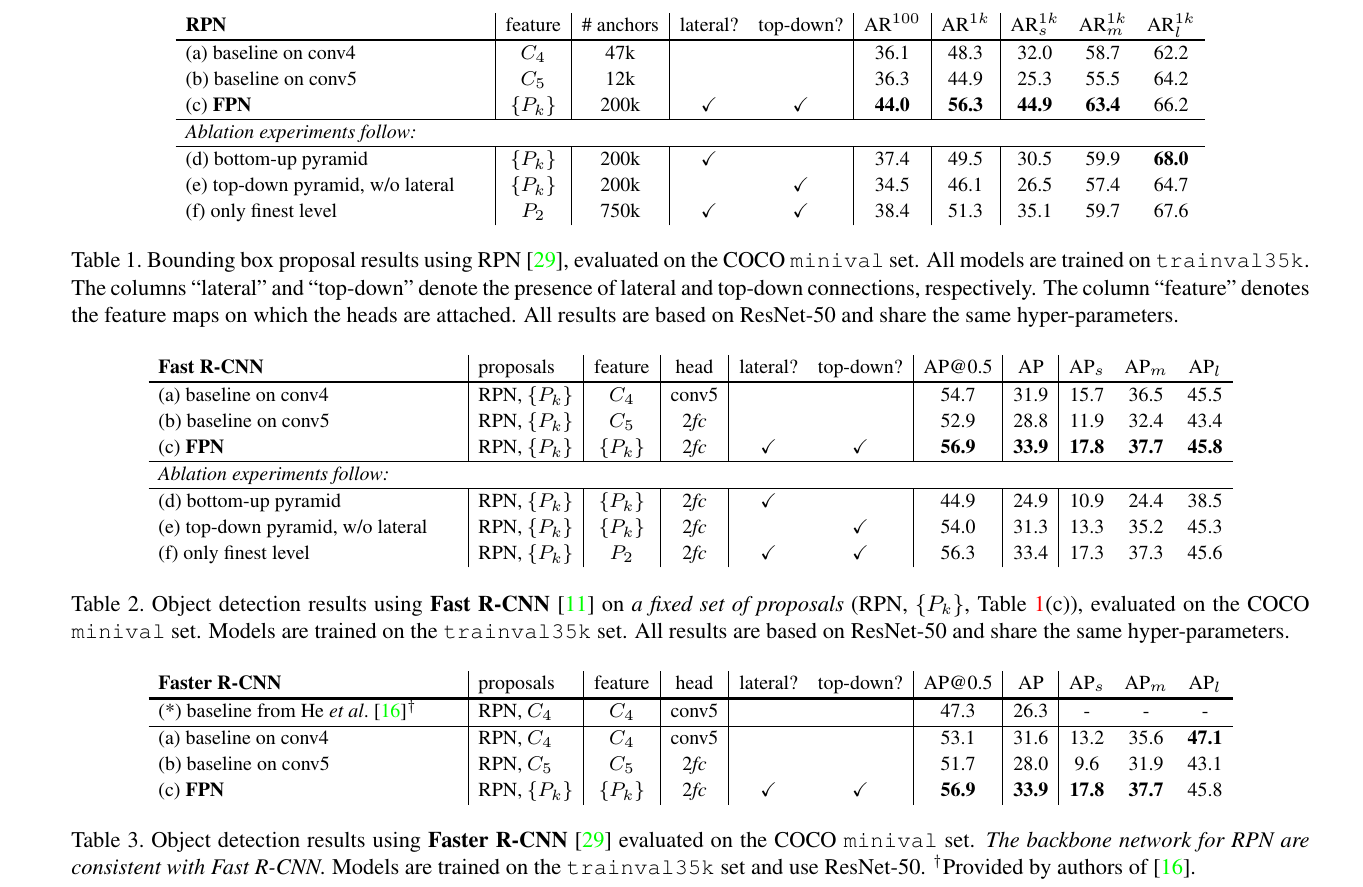
对比不同head部分,输入feature的变化对检测精度确实有提升,而且,lateral和top-down两个操作也是缺一不可。
Conclusion
特征金字塔本是很自然的想法,但如何构建金字塔同时平衡检测任务的定位和分类双目标,又能保证显存的有效利用,是本文做的比较好的地方。如今,FPN也几乎成为特征提取网络的标配,更说明了这种组合方式的有效性。
个人方面,FPN跟multi-scale的区别在哪,还值得进一步探索。