R-CNN系列的开山之作,2-stage的想法至今仍是精确度优先方法的主流。而且,本文中的众多做法也成为检测任务pipeline的标准配置。
摘要中提到的两大贡献:1)CNN可用于基于区域的定位和分割物体;2)监督训练样本数紧缺时,在额外的数据上预训练的模型经过fine-tuning可以取得很好的效果。
第一个贡献影响了之后几乎所有2-stage方法,而第二个贡献中用分类任务(Imagenet)中训练好的模型作为基网络,在检测问题上fine-tuning的做法也在之后的工作中一直沿用。
Intro
Features Matter. Traditional hand-design feature(SIFT, HOG) -> Learned feature(CNN). 从图像识别的经验来看,CNN网络自动习得的特征已经超出了手工设计的特征。
解决检测任务中的定位问题:”recognition using regions”,即基于区域的识别(分类)。
检测任务中样本不足的问题(对大型网络):在大数据集上预训练分类模型,在小数据集上fine-tuning检测任务。
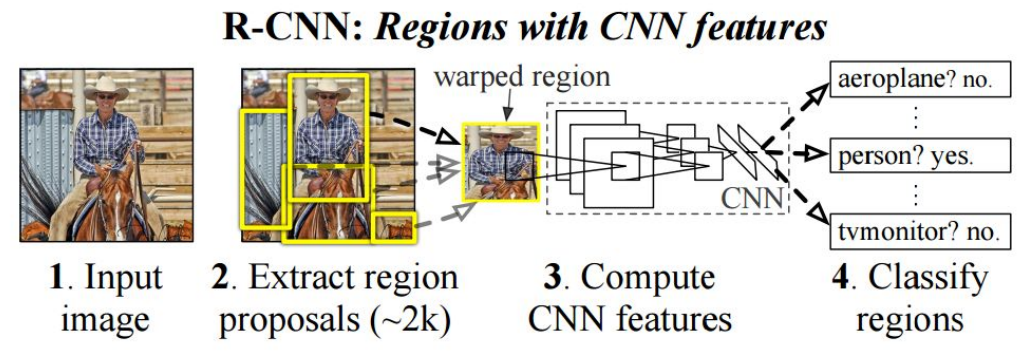
Object Detection with R-CNN
Region Proposal: Selective Search
Feature Extraction: AlexNet(NIPS 2012), 4096-dim feature vector from every region proposal
Training
现在ILSVRC2012上预训练达到STOA,再在Pascal VOC上fine-tuning。根据IOU来给region proposal打标签,在每个batch中保持一定的正样本比例(背景类非常多)。这些都已成为标准做法,后续很多工作也是对这些细节进行改进(OHEM等)。
文章中特别提到,IOU的选择(即正负样例的标签准备)对结果影响显著,这里要谈两个threshold,一个用来识别正样本(IOU跟ground truth较高),另一个用来标记负样本(即背景类),而介于两者之间的则为hard negatives,若标为正类,则包含了过多的背景信息,反之又包含了要检测物体的特征,因而这些proposal便被忽略掉。
另一个重要的问题是bounding-box regression,这一过程是proposal向ground truth调整,实现时加入了log/exp变换来使loss保持在合理的量级上。
Conclusion
R-CNN的想法直接明了,即是将CNN在分类上取得的成就运用在检测上,是深度学习方法在检测任务上的试水。模型本身存在的问题也很多,如需要训练三个不同的模型(proposal, classification, regression)、重复计算过多导致的性能问题等。尽管如此,这篇论文的很多做法仍然广泛地影响着检测任务上的深度模型革命,后续的很多工作也都是针对改进文章中的pipeline而展开,此篇可以称得上”the first paper”。