本文节选自博主通过格灵深瞳机构号发表在知乎上的文章:干货 | 目标检测入门,看这篇就够了。
目标检测的任务表述
如何从图像中解析出可供计算机理解的信息,是机器视觉的中心问题。深度学习模型由于其强大的表示能力,加之数据量的积累和计算力的进步,成为机器视觉的热点研究方向。
那么,如何理解一张图片?根据后续任务的需要,有三个主要的层次。
 图像理解的三个层次
图像理解的三个层次
一是分类(Classification),即是将图像结构化为某一类别的信息,用事先确定好的类别(string)或实例ID来描述图片。这一任务是最简单、最基础的图像理解任务,也是深度学习模型最先取得突破和实现大规模应用的任务。其中,ImageNet是最权威的评测集,每年的ILSVRC催生了大量的优秀深度网络结构,为其他任务提供了基础。在应用领域,人脸、场景的识别等都可以归为分类任务。
二是检测(Detection)。分类任务关心整体,给出的是整张图片的内容描述,而检测则关注特定的物体目标,要求同时获得这一目标的类别信息和位置信息。相比分类,检测给出的是对图片前景和背景的理解,我们需要从背景中分离出感兴趣的目标,并确定这一目标的描述(类别和位置),因而,检测模型的输出是一个列表,列表的每一项使用一个数据组给出检出目标的类别和位置(常用矩形检测框的坐标表示)。
三是分割(Segmentation)。分割包括语义分割(semantic segmentation)和实例分割(instance segmentation),前者是对前背景分离的拓展,要求分离开具有不同语义的图像部分,而后者是检测任务的拓展,要求描述出目标的轮廓(相比检测框更为精细)。分割是对图像的像素级描述,它赋予每个像素类别(实例)意义,适用于理解要求较高的场景,如无人驾驶中对道路和非道路的分割。
检测模型基本特点
深度学习方法主导下的检测模型,可以分为两阶段(two-stage)和单阶段(one-stage)。
 两阶段检测模型Pipeline,来源
两阶段检测模型Pipeline,来源
检测模型整体上由基础网络(Backbone Network)和检测头部(Detection Head)构成。前者作为特征提取器,给出图像不同大小、不同抽象层次的表示;后者则依据这些表示和监督信息学习类别和位置关联。检测头部负责的类别预测和位置回归两个任务常常是并行进行的,构成多任务的损失进行联合训练。
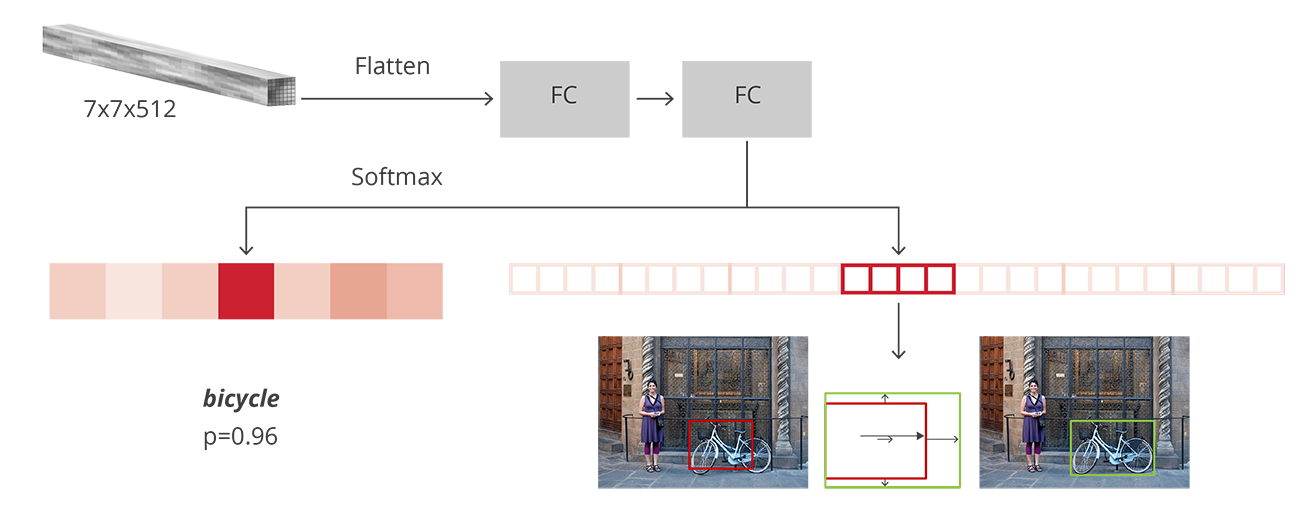 检测模型头部并行的分支,来源
检测模型头部并行的分支,来源
相比单阶段,两阶段检测模型通常含有一个串行的头部结构,即完成前背景分类和回归后,把中间结果作为RCNN头部的输入再进行一次多分类和位置回归。这种设计带来了一些优点:
- 对检测任务的解构,先进行前背景的分类,再进行物体的分类,这种解构使得监督信息在不同阶段对网络参数的学习进行指导
- RPN网络为RCNN网络提供良好的先验,并有机会整理样本的比例,减轻RCNN网络的学习负担
这种设计的缺点也很明显:中间结果常常带来空间开销,而串行的方式也使得推断速度无法跟单阶段相比;级联的位置回归则会导致RCNN部分的重复计算(如两个RoI有重叠)。
另一方面,单阶段模型只有一次类别预测和位置回归,卷积运算的共享程度更高,拥有更快的速度和更小的内存占用。读者将会在接下来的文章中看到,两种类型的模型也在互相吸收彼此的优点,这也使得两者的界限更为模糊。